Automatic Verification of Natural Language Claims
How to develop a model to verify a natural language statement while explaining its rationale?
Reading Time: About 10 minutes.
Paper:https://arxiv.org/abs/2012.13577
Code: https://github.com/jiangjiechen/LOREN
Demo: https://huggingface.co/spaces/Jiangjie/loren-fact-checking
Introduction

Contemporarily, the widespread use of the internet leads people to be more relying on it as an information source for news or life tips. However, though the information we get can be reliable the majority of the time,
it's still inevitable to have some rumors spreading across the internet. For instance, on Feb.7, an article published by the Washington Free Beacon claimed that "Biden Admin To Fund Crack Pipe Distribution To Advance ‘Racial Equity " [1] while the truth is quite opposite --- Biden didn't fund for crack pipes. How to have models to detect the truthfulness of these claims? Some studies have developed models on fact verification, but these models only give you the result of prediction and ignore the importance of providing reasons for that result. Nonetheless, we should not disregard the essentials of providing rationales for the fact verification result in order to convince audiences. Aim to solve this issue, the recent paper LOREN: Logic-Regularized Reasoning for Interpretable Fact Verification [2] introduced the LOREN method that can predict the veracity of a claim while generating rationales for the result.
In this article, I will introduce the model, LOREN, in three aspects:
Explain the LOREN'S architecture.
Analyze the performance of LOREN.
Possible improvements and potentials of LOREN.
LOREN'S architecture
Overall, LOREN's claim verification process is composed of these steps:
It decomposes a natural language statement into different phrase units.
For each phrase, LOREN generates a probing question and use it to retrieve relevant evidences, and then it establishes a local premise for that phrase.
Given the probing questions, evidences, and local premises, LOREN uses a latent model to aggregate the veracity of each phrase using three-valued soft logic, and it finally calculates the probability of the claim being supportive (SUP), refuted (REF), or not enough information (NEI).
The purpose of the first two steps is to look for the evidence that supports the phrase-level veracity, and by the means of soft logic, which I will introduce later in the article, we can verify the claim and provide reasoning behind it. Here is an example from the original paper that better illustrated the overall idea:
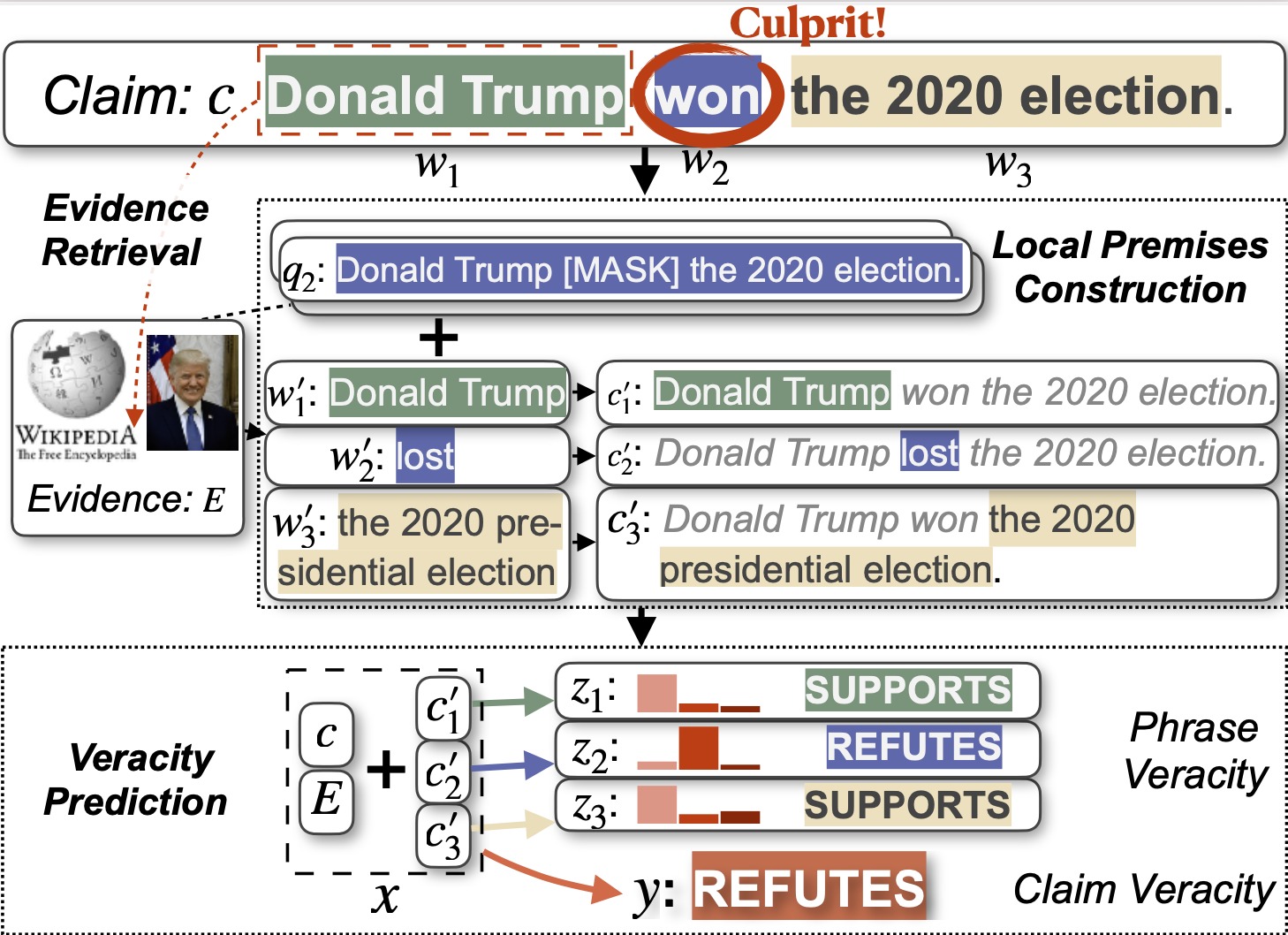
Decomposition of the claim
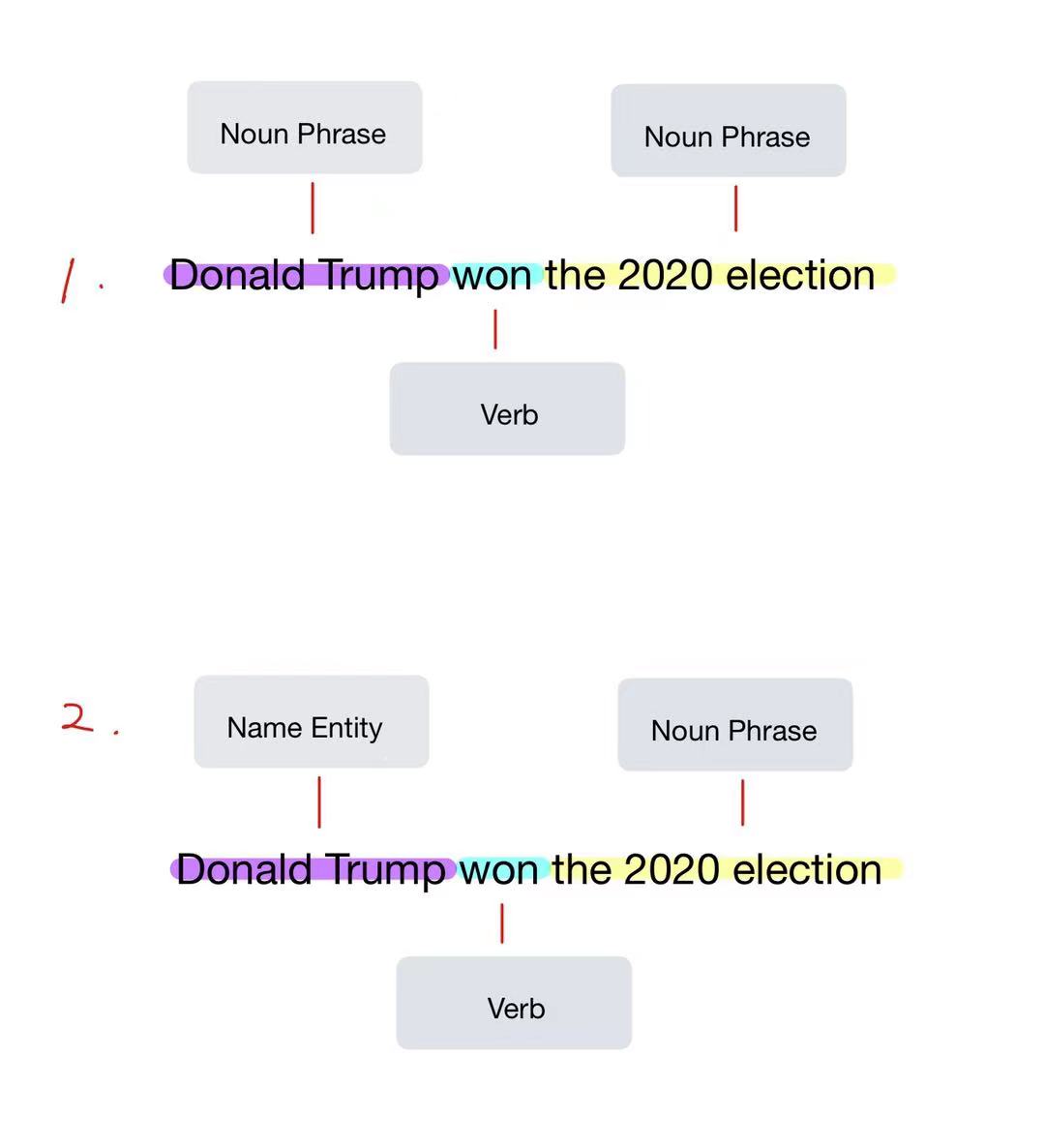
The above figure shows an example how LOREN decomposes the claim into phrases. The idea behind the claim decomposition is straightforward: We extract verbs, adjective phrases, noun phrases, and name entities from the claim. To ensure the accuracy of the decomposition, LOREN leverage a part-of-speech (POS) tagger for identifying verbs and a constituency parser to identify noun phrases [2] as presented by step 1 in the above example. To decompose these noun phrases into fine-grained phrases, it further uses POS tagger and name entity recognizer to extract adjective phrases, name entities, and fine-grained noun phrases from the original noun phrases (Step 2).
Probing questions generation, evidences retrieval, and local premises construction
Local premises are the collection of information to verify the veracity of each claim. [2] To construct local premises, we need probing questions and evidence as input. Regarding the probing questions, they consist of two sub-questions: one is the cloze question and another is the interrogative question. The cloze question is generated by masking out the phrase in the original claim and the interrogative question is generated by the off-the-shelf question generating model based on the T5 base. To better illustrate how LOREN generates probing questions, here is an example: For the phrase "Smriti Mandhana" in the claim "Smriti Mandhana is an Indian woman", the cloze question is "[MASK] is an Indian woman" and the iterrogative question is "Who is an Indian woman".
For the evidence retrieval part, we will assume it's done by an off-the-shelf technique, whose evidence source is Wikipedia, because the primary focus of LOREN is the fact verification (This results in a drawback of LOREN's lack of common sense knowledge, which I will address it later in the article). With probing questions and evidence, LOREN adopted the generative machine reading comprehension(MRC) model as a sequence-to-sequence model [3]. MRC model is self-supervised and based on evidence given for each phrase, it will generate answers for that phrase by answering its corresponding probing questions. Then it will replace the original phrase in the claim with answers to generate our local premises.
Latent model construction
Before we dive into the detail of latent model, let me introduce the logic constraints that LOREN developed for predicting claim veracity based on the veracity of each phrase.
- A claim is supportive(SUP) iff all phrases are supportive(SUP)
- A claim is refuted(REF) iff there's at least one phrase that is refuted(REF)
- A claim is non-enough-information(NEI) iff neither above.
Following the above logic rules, loren further soften these rules into a probability distribution.
where
- , which is the veracity of a claim.
- , which is the latent variable represents the veracity of a phrase.
- , which is the logic aggregation of the latent variable , meaning that is a categorical distribution over three labels .
The above aggregation of the soft logic serves to distill the knowldge to (Probability of the claim label given the phrase-level label and input x), which is the probability we eventually want to optimize.
Experiment
The model is trained on BERT and RoBERTa, and eventually it is evaluated on the dataset FEVER 1.0 shared task that is split into training, development and blind test set. Before we analyze the experiment result, I will summarize the experiment metrics they used to evaluate the performance[2]:
Experiment metrics for the performance of the model:
- Label Accuracy (LA): The accuracy of predicted label for claim regardless of retrieved evidence.
- FEVER score (FEV): The accuracy of both predicted label and retrieved evidence.
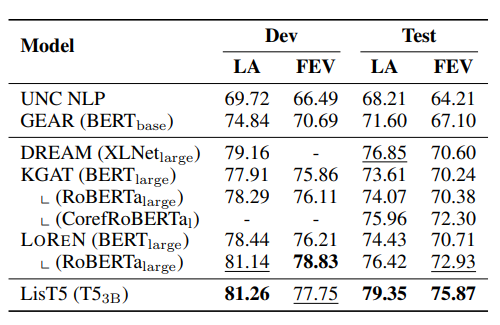
Let's look at the above overall performance of LOREN. We can see from the result that LOREN is either outperforming or comparable with other baseline method except for LisT5. This is mainly because the PLM for LisT5, which is T5, is larger than BERT and RoBERTa. However, LOREN still outperforms LisT5 on the FEVER score of the development set (dev). To summarize, the performance of LOREN is decent and it has the potential to achieve a better result.
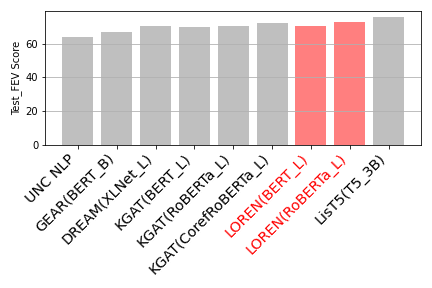
Here is a bar chart that can visualize LOREN's comparable test FEV score with other models:

In addition, we will dive into the most important part of the experiment: a case study of the LOREN's interpretability. For claim one in the above figure, LOREN can detect which phrase is the culprit in the claim, and it's also providing the reasoning that why that phrase is causing the mistake, i.e., replacing the false phrase "the number three" with "the number one". In the third claim, LOREN shows its ability to detect multiple culprit phrases in the claim. However, for the second claim, the predicted result should be NEI. LOREN made this mistake mainly because of the evidence retrieval module and MRC module. First, the evidence retrieval module did not draw the correct evidence, and then the MRC module still replaced the original phrase even though there's no direct evidence given. Here's some examples that indicates a drawback of LOREN:
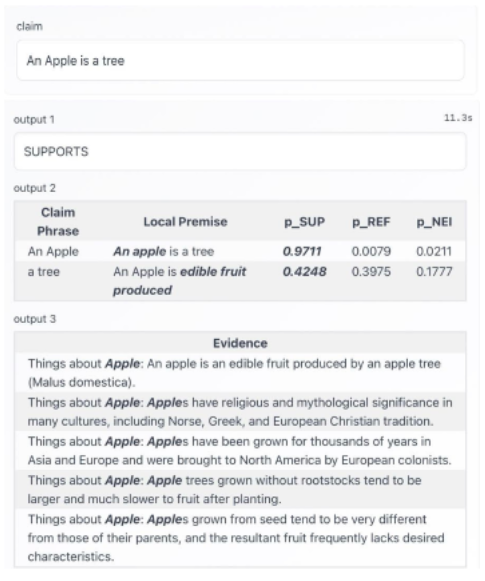
For the phrase "a tree" in the claim, even though LOREN generates the correct local premise based on the evidence, it still considers the label of this phrase as supported. It is because LOREN does not possess commonsense knowledge, and we can see the probability of SUP and REF are very close, indicating that LOREN fails to distinguish "tree" and "edible fruit produced" as two completely different objects.

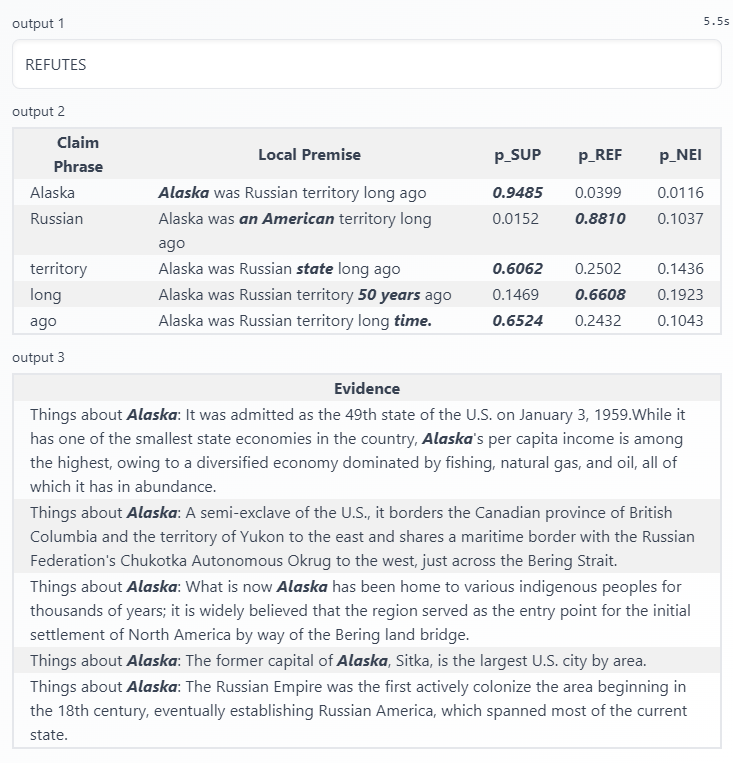
Here's another interesting example of LOREN's output. For the claim "Alaska was Russian territory long ago", though LOREN found the correct evidence, but it predicted the claim as REFUTES. It is confusing because the United States purchased Alaska on 1867, and before that time, Alaska is Russian territory. How did LOREN make this mistake? LOREN even has the evidence:"The Russian Empire was the first actively colonize the area beginning in the 18th century". In here I guess the reason's that LOREN does not consider Russian Empire is the same as Russian in the context of the claim, so I make another experiment by replacing "Russian" to "Russian Empire's":

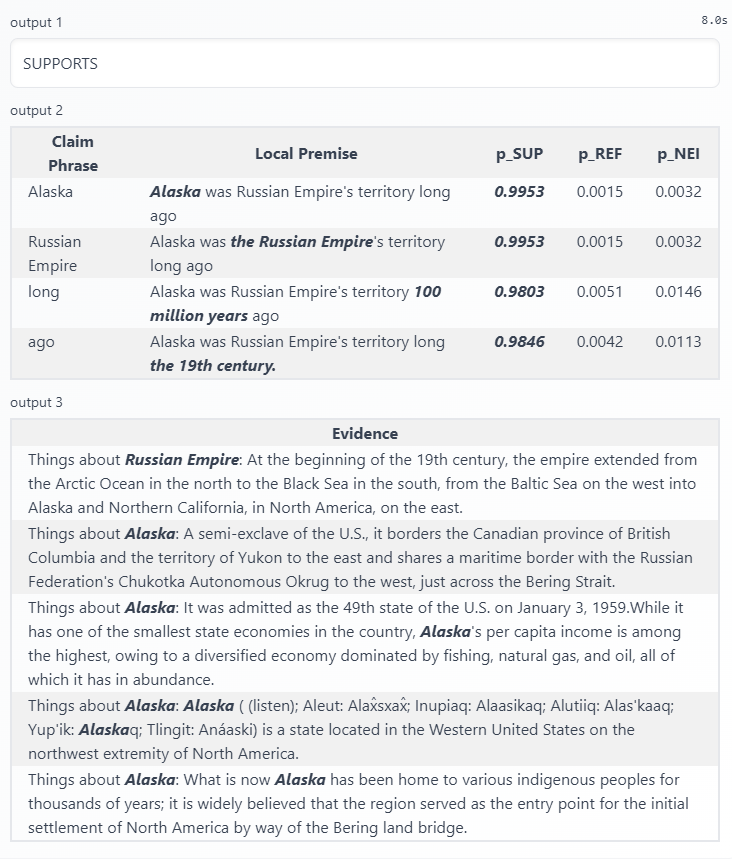
The result illustrated that LOREN knows Alaska was the territory of the Russian Empire since 1867. The former claim verification failed because LOREN can only predict based on the current evidence retrieved. In the last claim, LOREN does not have the evidence showing Russia is Russian Empire, so it eventually believes the claim is false. However, as humans, we always consider the Russian empire as Russia because it's the history of that country. But for LOREN in this case, it does not know about how a country is related to its history without enough evidence. The main cause of this result is also the immaturity of evidence retrieval. In the next step, I will show the potential problems within LOREN's MRC mode.
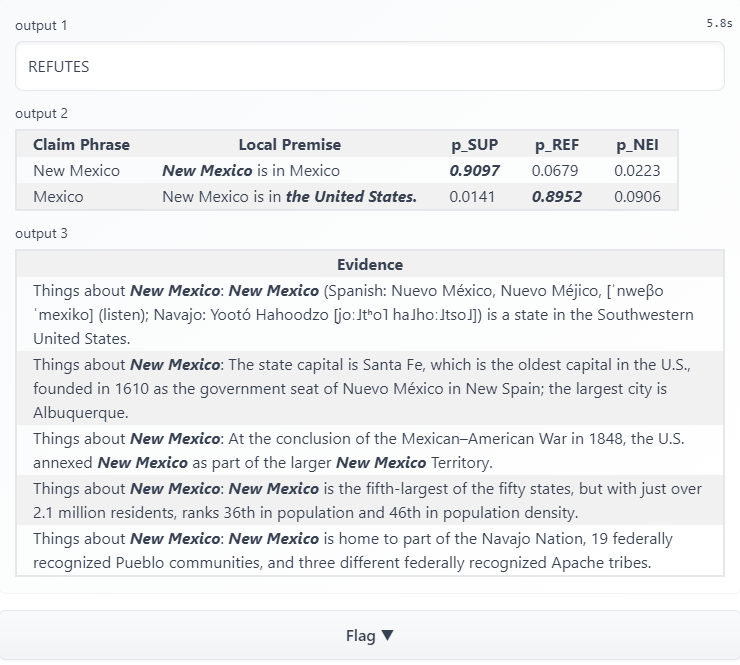
Here I provide a successful prediction outcome, and as we can see, LOREN's evidence retrival and MRC model work well in this prediction except that it fails to predict the first local premises to be refuted. However, when I change "is" to "is not", a more weird thing happens: LOREN's MRC model does not change the origin local premises in the last example:
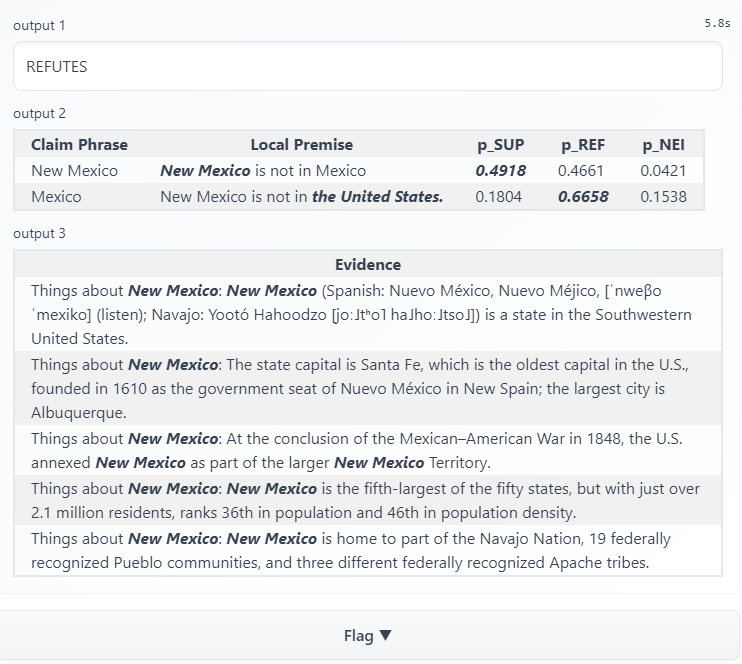
As we can see for the second phrase "Mexico", LOREN still replaces the phrase with "the United States" and even calculates a higher probability of refutes than supports. For now I'm not certain why LOREN behaves like this, but I have an assumption: LOREN's MRC model does not successfully interpret the claim. To be more specific, the prediction of the first phrase in these two examples are contradicting with each other, indicating that LOREN fails to interpret the difference between "is" and "is not", although its probability of supported and refuted are close to each other in the second example. Back to the local premises construction (MRC) for the second phrase, LOREN again fails to differentiate the meaning of "is" and "is not", so it has the same prediction for the veracity of second phrase as REF.

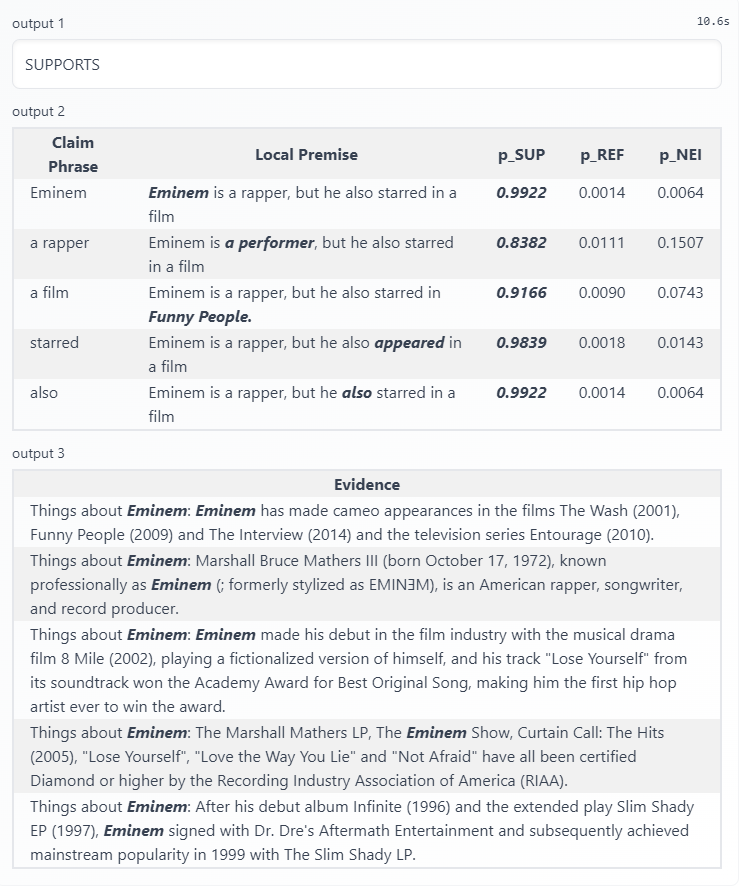
Despite some issues in evidence retrieval and MRC, LOREN can verify most claims given Wikipedia as the knowledge source. The above claim "Eminem is a rapper, but he also starred in a film" is a typical example where LOREN grabs the correct evidence and successfully verifies the claim as SUP. We know that Eminem is an influential rapper in the US, but lots of people do not know he is also an actor. In this case, for the phrase "a film" and "starred", LOREN retrieve the correct evidence, which is the first and third one. Then, LOREN's local premises construction for these two phrases also performs well: "Eminem is a rapper, but he also starred in Funny People" and "Eminem is a rapper, but he also appeared in a film", which results in the high probability of support. Eventually, LOREN considers this claim is SUP.
Future improvements
Since LOREN primarily focused on fact verification, so the evidence retrieval module in the model is immature. For the evidence retrieval part, LOREN directly adopts the retrieved results of KGAT which relies on the entity linking: sentence ranking pipeline. In other words, LOREN searches the name entity on Wikipedia and selects related sentences (evidence) based on a neural sentence ranking. Since evidence retrieved from Wikipedia is rich in encyclopedic knowledge but poor in commonsense knowledge, LOREN is biased toward this knowledge. Thus, how to train LOREN to understand common sense knowledge is worth exploring in the future. On the other hand, LOREN does not possess the power to verify the first-order logic claims, such as "All spiders are poisonous" or "There exists an apple that is not edible". Since in this case, if the evidence does not directly imply the correctness of the claim, LOREN may not be able (and it's also computationally inefficient) to search for all spiders to check if there exist some spiders that are not poisonous.
Conclusion
To verify the veracity of a claim, LOREN first computes the probability of the veracity of each phrase in the claim, and with the soft logics, it further aggregates the corresponding probabilities to predict the correctness of the claim. This method does well in verifying correctness of a claim and providing the related rationales.
References
[1] Patrick Hauf "Biden Admin To Fund Crack Pipe Distribution To Advance ‘Racial Equity’" the Washington Free Beacon, 2022.
[2] Jiangjie Chen, Qiaoben Bao, Changzhi Sun, Xinbo Zhang, Jiaze Chen, Hao Zhou, Yanghua Xiao, and Lei Li. "LOREN: Logic-Regularized Reasoning for Interpretable Fact Verification", AAAI, 2022