机器翻译中的 BERT 应用
预训练技术,比如 BERT等,在自然语言处理领域,尤其是自然语言理解任务取得了巨大的成功。然而目前预训练技术在文本生成领域,比如机器翻译领域,能够取得什么样的效果,还是一个开放问题。CTNMT 这篇论文,从三个方面介绍这个问题:
- 预训练技术,比如 BERT或者 GPT 在机器翻译中的应用存在什么挑战?
- 针对这些调整,需要怎么最大程度利用预训练知识?
- 预训练和机器翻译的融合还有什么潜力?
阅读时间大概 10 分钟。论文链接:https://arxiv.org/abs/1908.05672
预训练技术在机器翻译领域存在的挑战—-灾难性遗忘
机器翻译和传统自然语言处理很大的一个差异点在于有海量训练数据。很多自然语言处理任务,比如 SRL、POS等任务,训练数据一般只有3-10 万句规模,但是机器翻译任务的数据量一般都是千万级别,比如 WMT En-Fr 有 4000 万平行数据。如此大的数据量就给预训练模式带来了挑战。因为一般预训练模式,都是在较大的训练数据上预训练模型,接下来再一个小数据上进行微调模型,这样模型保留了大数据的知识,又可以适应小模型的数据,因而会有不错的表现。但是,对于机器翻译来说,下游任务的微调需要更多步骤,和更久的时间,一个直接影响就是灾难性遗忘,也就是模型随着不断微调逐渐忘记了预训练的知识,那么预训练模型的威力就很难在下游任务中得到体现。
渐进式学习策略--缓解灾难性遗忘问题
基于对灾难性遗忘的假设,CTNMT 提出了三种策略来逐步缓解问题。
- 最简单的也是最直接的通过学习率来控制,有效但是实际操作需要比较仔细的参数控制策略。
- 动态的基于门控制策略,由模型来决定预训练模型参数和机器翻译模型参数的贡献比例。
- continues learning 中最常见的策略,通过知识蒸馏来保持预训练模型的知识在下游微调中不要被忘记。
这篇工作最重要的贡献并不是提出了这三种 technical 策略,更有趣的地方在于指出了机器翻译预训练微调框架中存在的问题,以及提出了几个简单的方法,验证了假设,并且在机器翻译benchmark 任务中观察到了显著提升。
梯度控制
最简单的策略是在下游任务更新的时候,控制BERT 的学习率,将 BERT 的学习控制在一个比较小的范围。不同于其它 NLP 任务,对于机器翻译来说,BERT 作为 Encoder 只占了整体参数中一半的参数量,还有另外一半没有被初始化,如果一开始所有参数一起调整,随机初始化的参数传递的梯度会有大量噪音,这部分噪音会很大程度影响 BERT 的参数,因此最优的策略应该是一开始固定 BERT 参数,先更新随机初始化部分的参数,当这部分参数更新差不多的时候,再打开 BERT 参数,然后一起更新着两部分参数,更新一定步骤之后,再将 BERT 参数固定下来,只更新 MT 部分的参数,这样就可以很大程度上避免了灾难性遗忘的问题,而且也可以让参数更好的适应下游任务,最大程度利用到预训练知识。
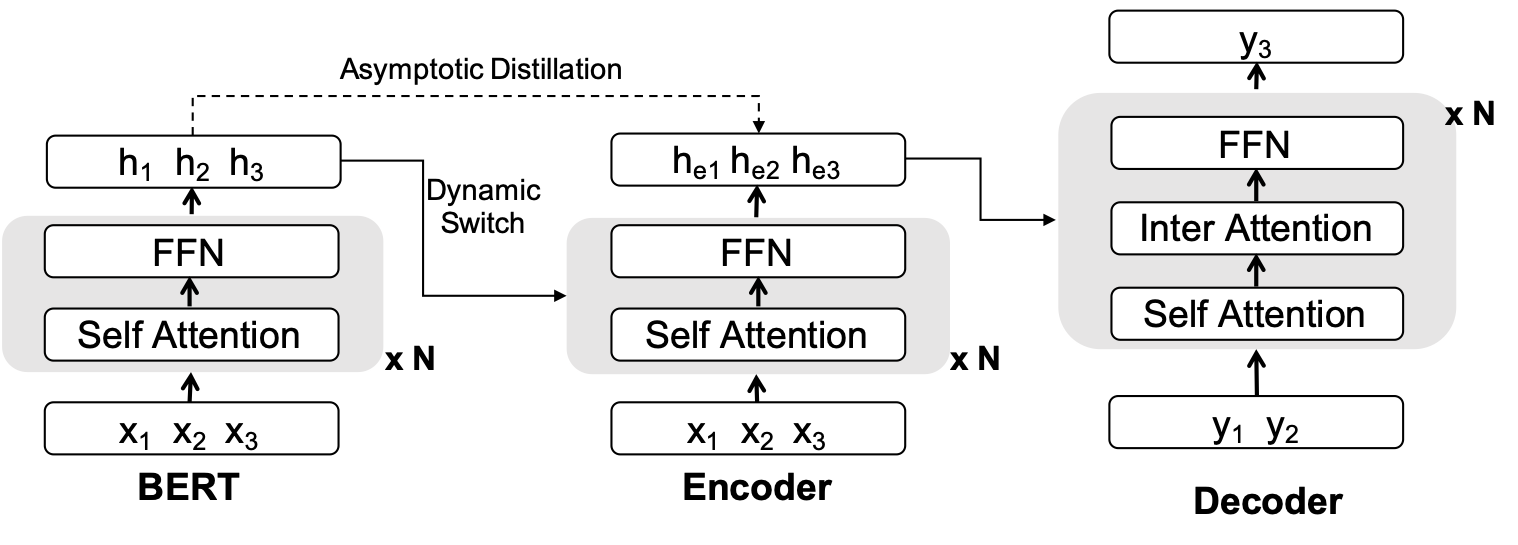
基于门控制的融合
梯度控制简单有效,但是很大的一个问题在于需要超参来控制 BERT 参数更新的开始和结束,因此 CTNMT 又引入了门机制来更自动的控制这种更新。简单说门机制引入一个可学习的参数控制 BERT 和 MT Encoder 贡献的比例,实际上这个参数也可以反过来控制更新的程度,有了这种自动控制机制,模型就可以将机器翻译和 BERT 有机结合起来,也可以很好的避免灾难性遗忘问题。

渐进蒸馏策略
持续学习中一个重要的方法就是蒸馏策略,也就是学生不断学习老师的知识,这样学生网络在不断更新的情况下,也可以保持不忘记老师的知识,在这个工作中,我们将 BERT 看作老师,将 MT Encoder看作学生。 这样就可以同时保持机器翻译参数的灵活性和保留 BERT 知识,最重要的是,这种方法只需要更改模型训练,对于模型解码不需要有任何更改,非常实用。
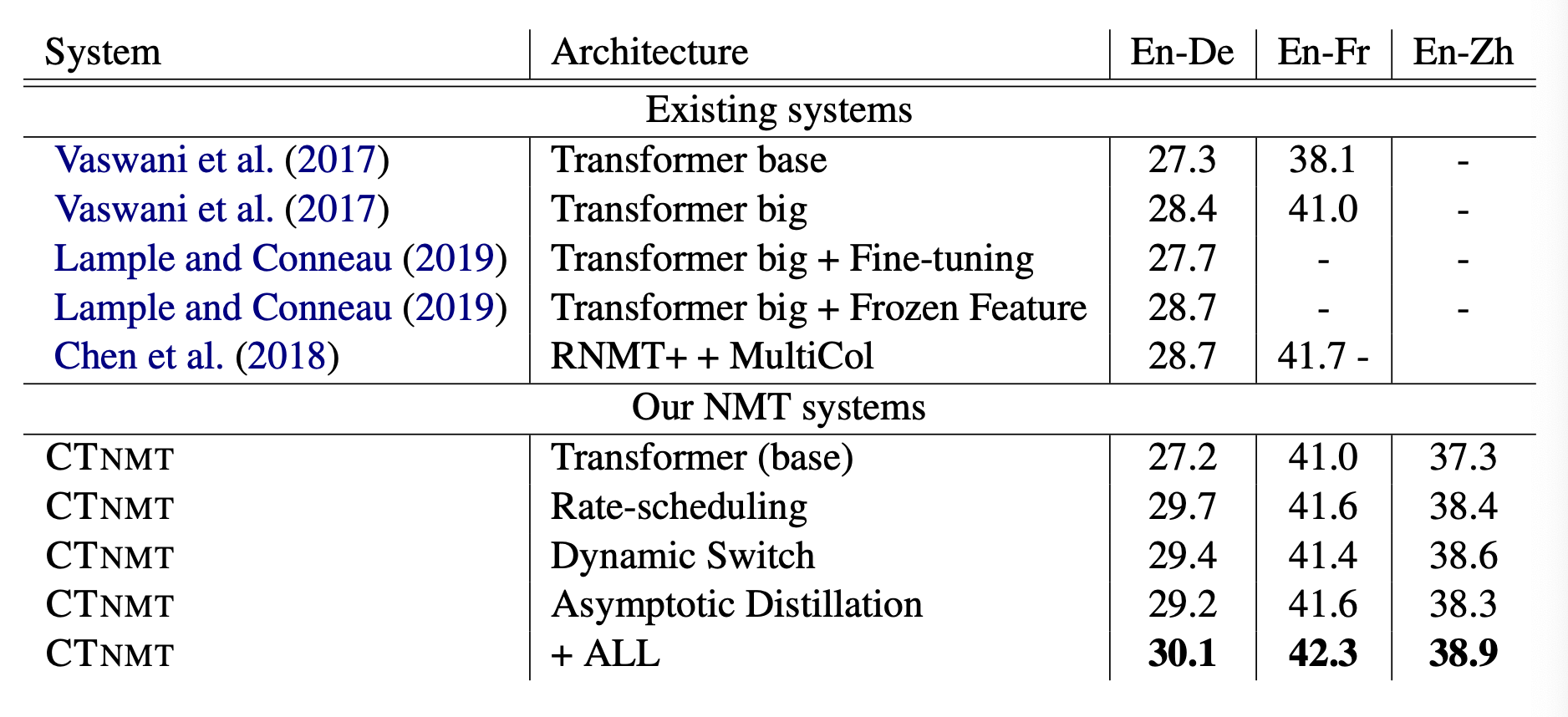
实验效果和未来方向
CTNMT 在主流的 En-Fr、En-De 和 Zh-En 三个 WMT 语种上都做了实验,这三个数据也是业界比较公认的 Benchmark,通过下图的实验可以发现,三个单独的策略都起到了很明显的作用,更有趣的是,这三个方法加在一起还可以进一步提升模型效果。在英德方向上,最后实验得到了 30.1 的 BLEU score,相比 baseline 提升了接近三个点。
接下来 CTNMT 分析了数据量和效果之间的关系,可以发现在数据量比较少的时候,普通的 fine-tuning 和CTNMT 的方法差异非常小,这个原因主要是数据量少的时候灾难性遗忘的问题不是很严重,直接做 fine-tuning 就可以了。但是数据量增大的时候,可以发现,fine-tuning 的提升 gap 就会相对下降,这是由于随着数据量的增大,灾难性遗忘引起的问题越来越显著。但是 CTNMT 可以很好的避免这种遗忘,因而保持了稳定的提升。

此外,也简单做了一些关于 GPT 和 BERT 的模型选择实验,发现简单的再 encoder 和 decoder 使用 GPT 或者 BERT 效果并不是一样好,总结来说:
- Encoder 采用 BERT 初始化效果最好
- Decoder采用 BERT 或者 GPT 初始化,效果不明显
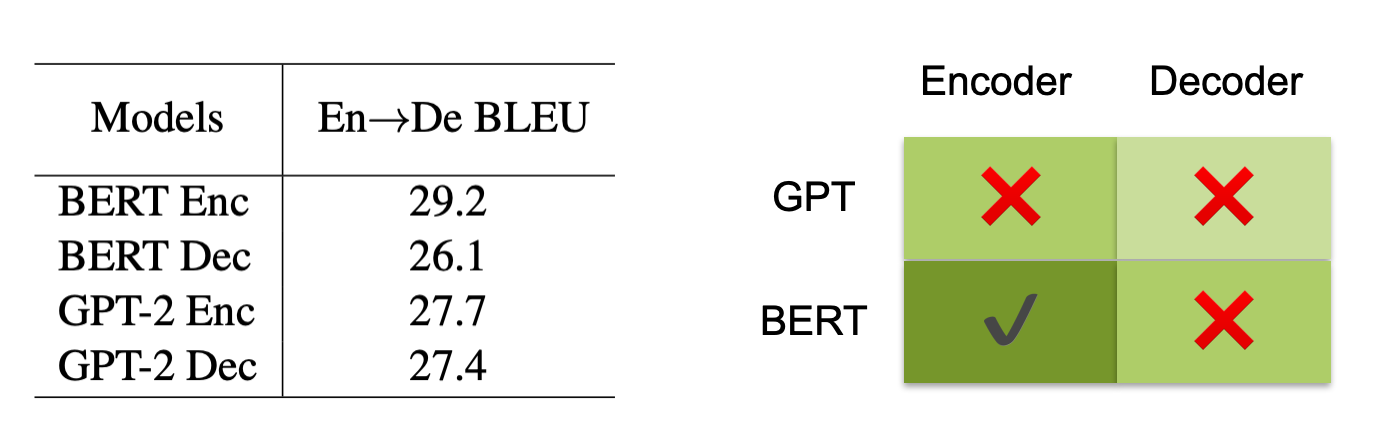
直觉上讲,Decoder 对于机器翻译也起到了非常重要的作用,目前只初始化 Decoder,可能分布不一样,并且 Decoder 和 Encoder 之间有 attention,这部分也没有办法初始化,所以局部的 pre-training 还有很大的提升空间。因此,未来如何研究更好的将 Decoder 预训练和 Encoder预训练结合起来,得到进一步提升,是非常有潜力的方向。