Revisiting Self-training for Neural Sequence Generation
Self-training is a very prevalent semi-supervised method. Its key idea is to augment the original labeled dataset with unlabeled data paired with the model's prediction (i.e. the pseudo-parallel data). Self-training has been widely used in classification tasks. However, will it work on sequence generation tasks (e.g. machine translation)? If so, how does it work? This blog introduces a work [1] which investigates these questions and gives the answers.
Reading Time: About 10 minutes.
Paper:https://arxiv.org/abs/1909.13788
Github: https://github.com/jxhe/self-training-text-generation
1. Introduction
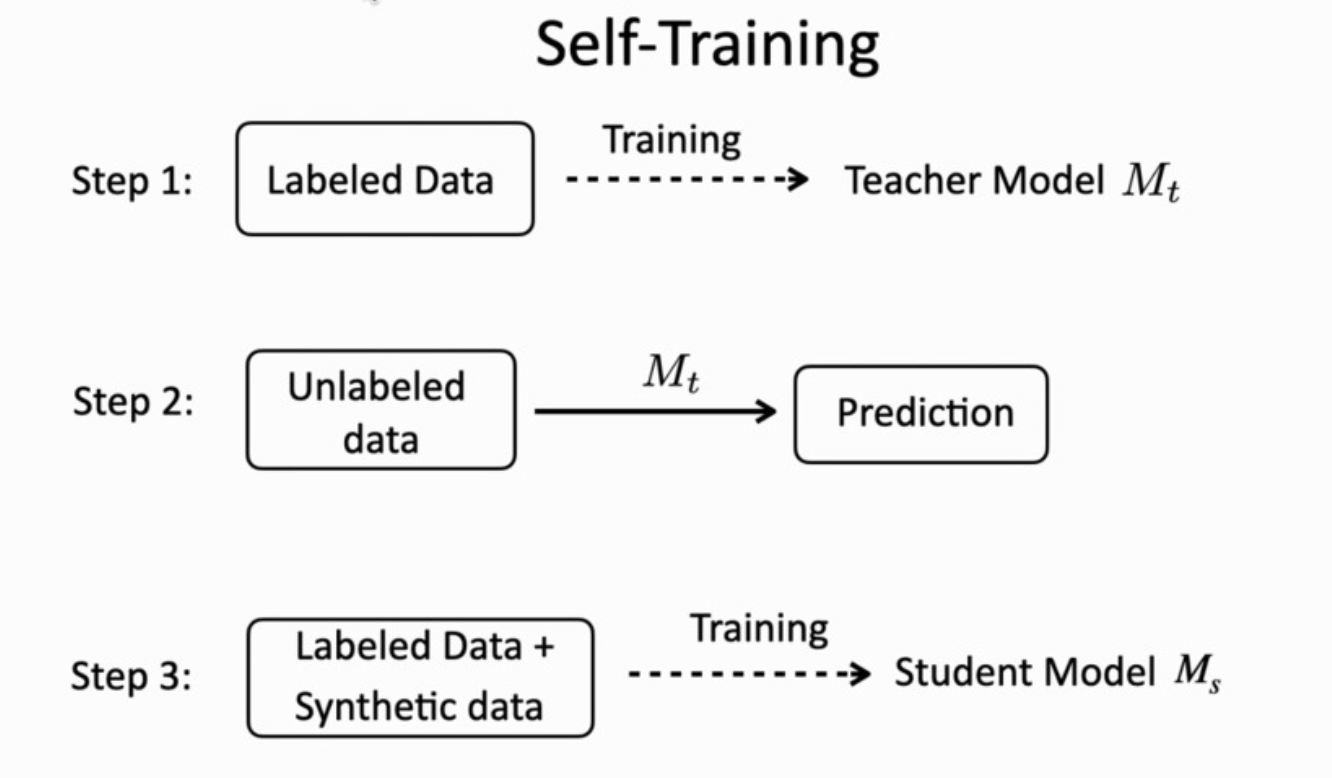 Deep neural networks often require large amounts of labeled data to achieve good performance. However, it is very costly to acquire labels. So what if there is not enough labeled data? Researchers try to fully utilize the unlabeled data to improve the model performance. Self-training is a simple but effective method. As can be seen in the figure above, in self-training, a base model trained with labeled data acts as a “teacher” to label the unannotated data, which is then used to augment the original small training set. Then, a “student” model is trained with this new training set to yield the final model. Self-training is originally designed for classification problems, and it is believed that this method may be effective only when a good fraction of the predictions on unlabeled samples are correct, otherwise errors will be accumulated.
Deep neural networks often require large amounts of labeled data to achieve good performance. However, it is very costly to acquire labels. So what if there is not enough labeled data? Researchers try to fully utilize the unlabeled data to improve the model performance. Self-training is a simple but effective method. As can be seen in the figure above, in self-training, a base model trained with labeled data acts as a “teacher” to label the unannotated data, which is then used to augment the original small training set. Then, a “student” model is trained with this new training set to yield the final model. Self-training is originally designed for classification problems, and it is believed that this method may be effective only when a good fraction of the predictions on unlabeled samples are correct, otherwise errors will be accumulated.
However, self-training has not been studied extensively in neural sequence generation tasks like machine translation, where the target output is natural language. So the question arises: can self-training still be useful in this case? Here we introduce a work [1] which investigate the problem and answer the two questions:
- How does self-training perform in sequence generation tasks like machine translation?
- If self-training helps improving the baseline, what contributes to its success?
2. Case Study on Machine Translation
The authors first analyze the machine translation task, and then perform ablation analysis to understand the contributing factors of the performance gains.
They work with the standard WMT 2014 English-German dataset. As a preliminary experiment, they randomly sample 100K sentences from the training set (WMT100K) and use the remaining English sentences as the unlabeled monolingual data. They train with the Base Transformer architecture and use beam search decoding (beam size 5).
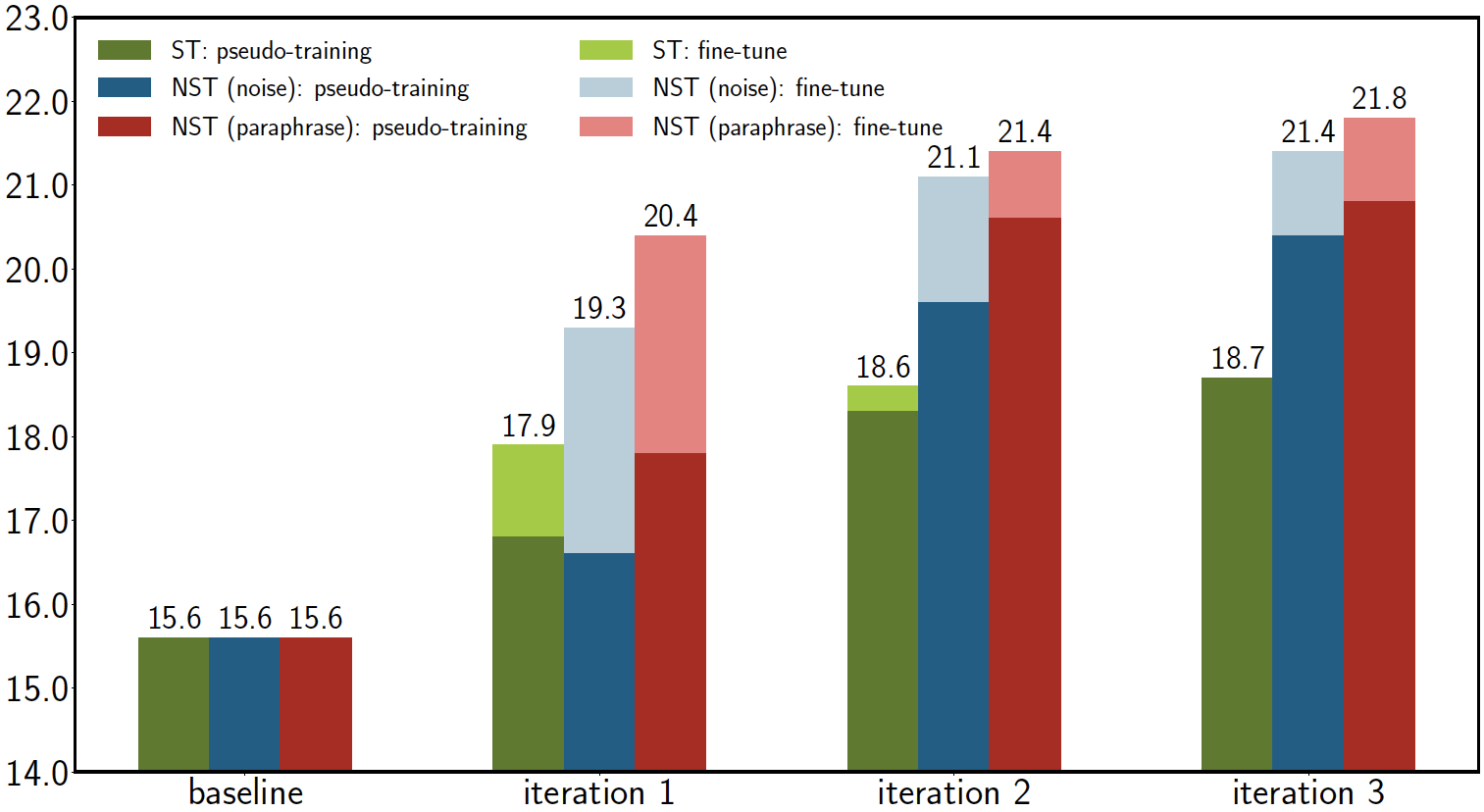 Green bars in the above figure shows the result of applying self-training for three iterations, which includes:
Green bars in the above figure shows the result of applying self-training for three iterations, which includes:
- Pseudo-training (PT): the first step of self-training where we train a new model (from scratch) using only the pseudo parallel data generated by the current model
- Fine-tuning (FT): the fine-tuned system using real parallel data based on the pretrained model from the PT step.
It is surprising that the pseudo-training step at the first iteration is able to improve BLEU even if the model is only trained on its own predictions, and fine-tuning further boosts the performance. An explanation is that the added pseudo-parallel data might implicitly change the training trajectory towards a (somehow) better local optimum, given that we train a new model from scratch at each iteration.
| Methods | PT | FT |
|---|---|---|
| baseline | - | 15.6 |
| baseline (w/o dropout) | - | 5.2 |
| ST (beam search, w/ dropout) | 16.5 | 17.5 |
| ST (sampling, w/ dropout) | 16.1 | 17.0 |
| ST (beam search, w/o dropout) | 15.8 | 16.3 |
| ST (sampling, w/o dropout) | 15.5 | 16.0 |
| Noisy ST (beam search, w/o dropout) | 15.8 | 17.9 |
| Noisy ST (beam search, w/ dropout) | 16.6 | 19.3 |
3. The Secret Behind Self-training
To decode the secret of self-training and understand where the gain comes from, they formulate two hypotheses:
Decoding Strategy: According to this hypothesis, the gains come from the use of beam search for decoding unlabeled data. The above table shows the performance using different decoding strategies. As can be seen, the performance drops by 0.5 BLEU when the decoding strategy is changed to sampling, which implies that beam search does contribute a bit to the performance gains. This phenomenon makes sense intuitively since beam search tends to generate higher-quality pseudo targets than sampling. However, the decoding strategy hypothesis does not fully explain it, as there is still a gain of 1.4 BLEU points over the baseline from sampling decoding with dropout.
Dropout: The results in the above table indicate that without dropout the performance of beam search decoding drops by 1.2 BLEU, just 0.7 BLEU higher than the baseline. Moreover, the pseudo-training performance of sampling without dropout is almost the same as the baseline.
In summary, beam-search decoding contributes only partially to the performance gains, while the implicit perturbation i.e., dropout accounts for most of it. The authors also conduct experiment on a toy dataset to show that noise is beneficial for self-training because it enforces local smoothness for this task, that is, semantically similar inputs are mapped to the same or similar targets.
4. The Proposed Method: Noisy Self-training
To further improve performance, the authors considers a simple model-agnostic perturbation process - perturbing the input, which is referred to as noisy self-training. Note that they apply both input perturbation and dropout in the pseudo-training step for noisy ST. They first apply noisy ST to the WMT100K translation task. Two different perturbation function are tested:
- Synthetic noise: the input tokens are randomly dropped, masked, and shuffled.
- Paraphrase: they translate the source English sentences to German and translate it back to obtain a paraphrase as the perturbation.
Figure 2 shows the results over three iterations. Noisy ST greatly outperforms the supervised baseline and normal ST, while synthetic noise does not exhibit much difference from paraphrase. Since synthetic noise is much simpler and more general, it is defaulted in Noisy ST. Table 1 also reports an ablation study of Noisy ST when removing dropout at the pseudo-training step. Noisy ST without dropout improves the baseline by 2.3 BLEU points and is comparable to normal ST with dropout. When combined together, noisy ST with dropout produces another 1.4 BLEU improvement, indicating that the two perturbations are complementary.
5. Experiments
Machine Translation
The author test the proposed noisy ST on a high-resource MT benchmark: WMT14 English-German and a low-resource one: FloRes English-Nepali.
| Methods | WMT14 100K | WMT14 3.9M | FloRes En-Origin | FloRes Ne-Origin | FloRes Overall |
|---|---|---|---|---|---|
| baseline | 15.6 | 28.3 | 6.7 | 2.3 | 4.8 |
| BT | 20.5 | - | 8.2 | 4.5 | 6.5 |
| Noisy ST | 21.4 | 29.3 | 8.9 | 3.5 | 6.5 |
The overall results are shown in the above table. For almost all cases in both datasets, the noisy ST outperforms the baselines by a large margin, and noisy ST still improves the baseline even when this is very weak.
Comparison with Back Translation
It can be seen that noisy ST is able to beat BT on WMT100K and on the en-origin test set of FloRes. In contrast, BT is more effective on the ne-origin test set according to BLEU, which is not surprising as the ne-origin test is likely to benefit more from Nepali than English monolingual data.
Analysis
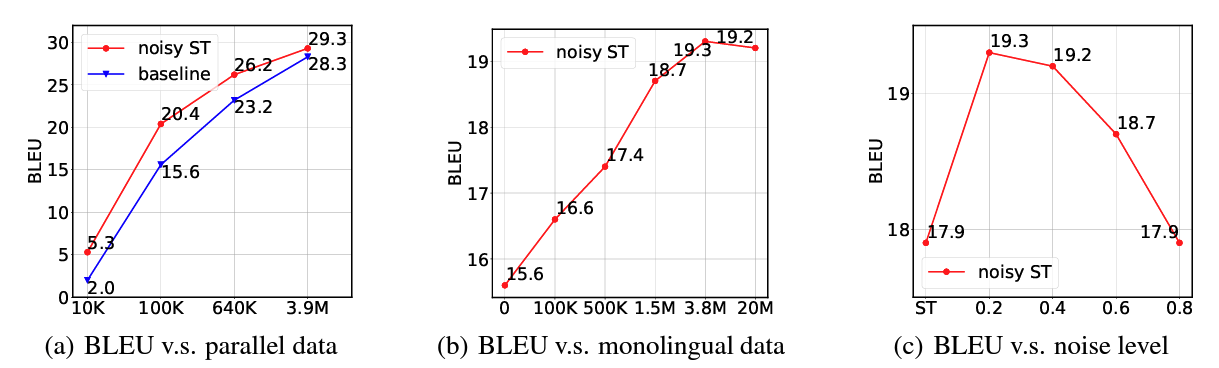
The authors analyze the effect of the following three factors on noisy self-training on the WMT14 dataset:
- Parallel dat size
- Monolingual dat size
- Noise level The result is shown in the above figure. In (a) we see that the performance gain is larger for intermediate value of the size of the parallel dataset, as expected. (b) illustrates that the performance keeps improving as the monolingual data size increases, albeit with diminishing returns. (c) demonstrates that performance is quite sensitive to noise level, and that intermediate values work best. It is still unclear how to select the noise level a priori, besides the usual hyper-parameter search to maximize BLEU on the validation set.
Summary
This work revisit self-training for neural sequence generation, especially machine translation task. It is shown that self-training can be an effective method to improve generalization, particularly when labeled data is scarce. Through comprehensive experiments, they prove that noise injected during self-training is critical and thus propose to perturb the input to obtain a variant of self-training, named noisy self-training, which show great power on machine translation and also text summarization tasks.
References
[1] He, Junxian, et al. "Revisiting Self-Training for Neural Sequence Generation." International Conference on Learning Representations. 2019.