Generative Pre-trained Transformer (GPT)
In the past couple years, we have seen the rise of Transformer architectures in Natural Language Processing. Transformers revolutionized the speed and accuracy of machine translation systems, and alleviated the need for Recurrent Neural Networks and LSTMs to derive context and meaning for sequence to sequence modeling. Since the Attention Is All You Need paper was published in 2017, there have been many experimental application and fine-tuning improvements made upon the original model. The latest such improvement is the Generative Pre-Trained Transformer 3, or GPT-3.
GPT-3 is the third generation of the autoregressive language modeling GPT-n series created by OpenAI. Its architecture is exactly the same as the previous generation, GPT-2, with the exception of using alternating dense and locally banded sparce attention patterns. For this generation, OpenAI trained 8 different models with a variable number of parameters, layers, dimensions, learning rates, and batch sizes. Furthermore, unlike the GPT-2 which was trained on the WebText dataset, GPT-3 was trained on Common Crawl, which consists of nearly a trillion words. However, because this dataset is so large and unfiltered, various techniques had to be used to prevent overfitting the model and data contaimination.
Novelty
Aside from the changes made above to the new model, the novelty of GPT-3 stems from its ability to use one-shot and few-shot demonstrations — it is not limited to zero-shot like GPT-2. To be more specific, this means that before actually testing GPT-3 on a specific task, the model can take a certain amount of examples K of the desired task as a form of conditioning before letting the model perform testing and inference on its own. For one-shot demonstrations, K is 1, and for few-shot demonstrations, K can be anywhere between 10 and 100 demonstrations of the task. This may sounds similar to fine-tuning a model, but there is one key difference: for these n-shot demonstrations, the model is NOT allowed to update its weights whereas for fine-tuning, the model is supposed to update its weights. This novel approach of providing demonstrations before actual testing was specifically chosen because it best simulates human learning and behavior. Typically, when people are told to complete a task, they are usually offered one or more examples before having to attempt the task on their own. The table below illustrates the advantages and disadvantages of each of the different types of n-shots for GPT-3.
| Type | Advantages | Disadvantages |
|---|---|---|
| Fine Tuning | Strong performance on a specific task | The need for an new, large dataset for the specific task |
| Few-Shot | Major reduction in the need for task specific data and examples | Potential for much worse performance than state-of-the-art fine tuned models |
| One-Shot | Most closely related to the way tasks are communicated to humans | Performs worse than Few-Shot |
| Zero-Shot | Most convenient and no need for additional data | Most challenging setting, humans cannot even perform some tasks without examples |
Evaluation on Various Tasks
With these new types of testing and inference methods, GPT-3 was evaluated on a variety of NLP tasks that include text translation, generation, prediction, and comprehension. This fact alone — that one single model is able to be evaluated on a range of tasks — shows how powerful and exciting GPT-3 is. Prior to GTP-3, models had to be explicitly trained to do a specific task. In the following subsections, when describing the evaluations and accuracy for the different use cases, you will see that GPT-3 is powerful enough to match or even outperform some state-of-the-art models for NLP tasks.
Translation
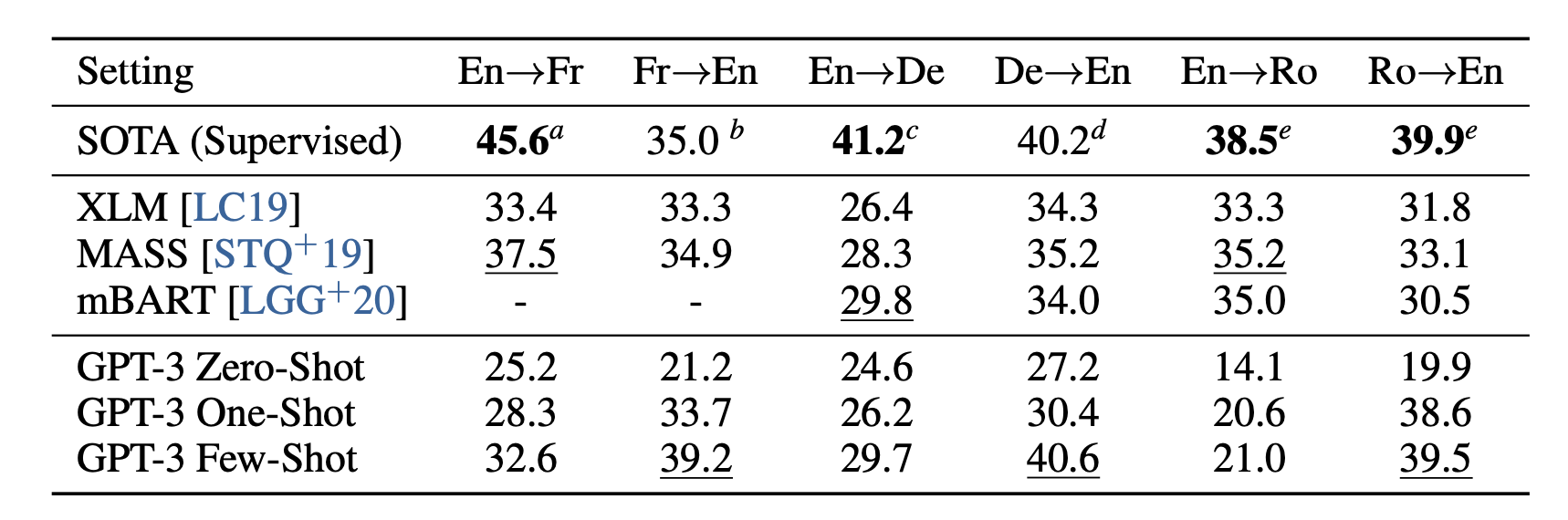
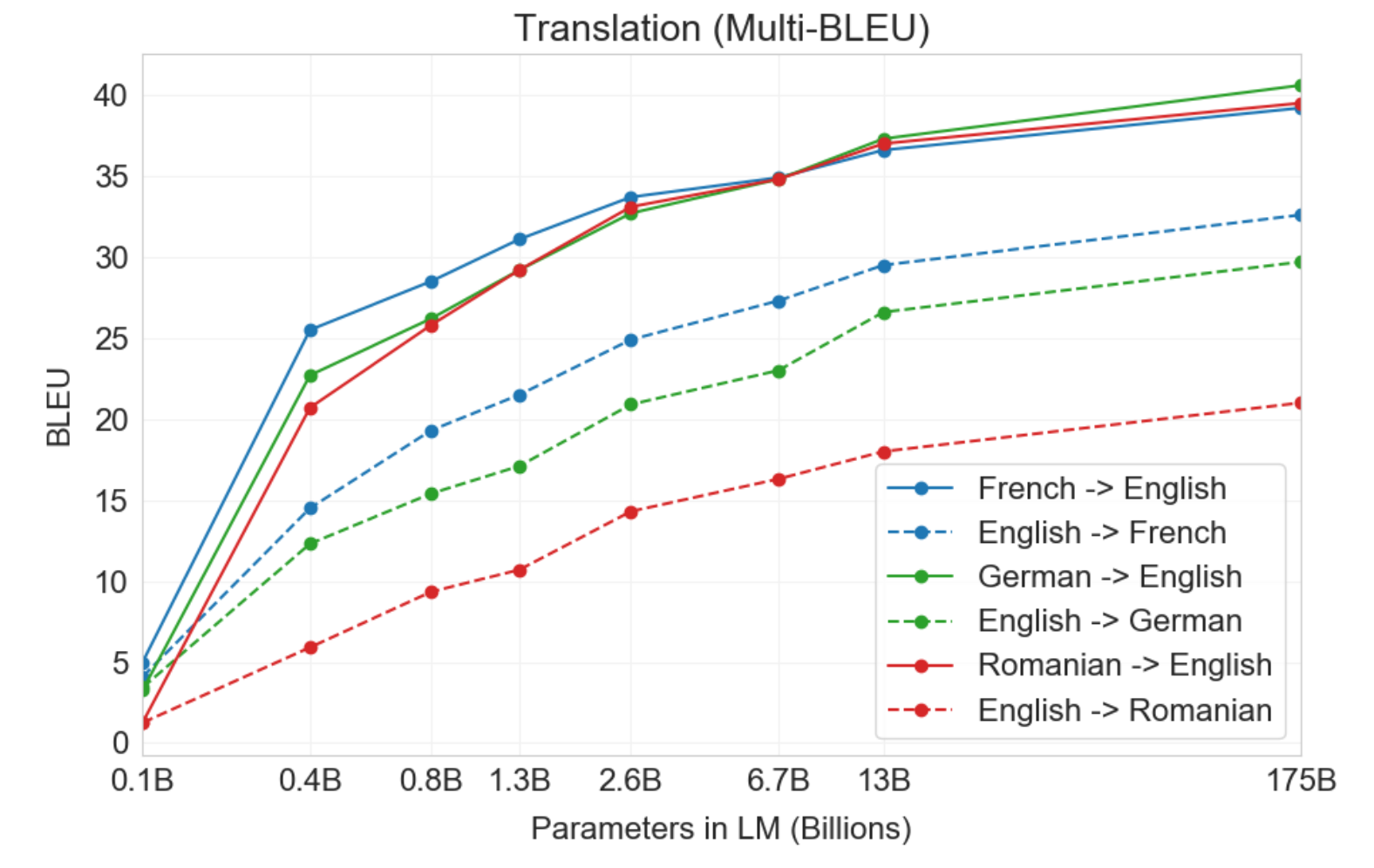
One of the tasks GPT-3 was tested on was its ability to perform sequence to sequence translation. The Common Crawl dataset OpenAI used to train their model contained English words 93% of the time and words from foreign languages 7% of the time. The words from the foreign natural languages were seamlessly blended together with the English text on a word, sentence, and document level. This allowed for the model to extract meaning and context from the foreign words, and be able to accurately translate them when asked to do so. From this translation test, GPT-3 resulted in a similar BLEU score compared to prior unsupervised NMT work. While zero-shot underperformed compared to prior works, one-shot improved the BLEU score by 4 and few-shot improved the BLEU score by 11. BLEU score improvement was especially noticed when translating phrases into English as opposed to translating sentence from English. In fact, some translations from English even outperform the best supervised results. The table and graph below shows the comparison of BLEU scores for each of the different n-shots and other NMT models, and how BLEU score changes with model size.
Word Prediction and Text Generation
Another task GPT-3 was tested on was predicting the next word given a few sentences or a passage. A demonstration along the lines of Alice was friends with Bob. Alice went to visit her friend __. → Bob was given to the model as an example along with a task description. From examples like these, the largest GPT-3 model (with 175 billion parameters) outperformed the current state-of-the-art model by 20%, predicting the next word correctly 86.4% of the time. Even if a model was trained on this specific task and outperformed a state-of-the-art model by 20%, it would still be extraordinary.
Another simliar test using GPT-3 was news article generation. The model was given a number of news articles written by humans as conditioning, and asked to generate a news article itself. Because this task is difficult to measure quantitatively, they measured the performance of the task based on whether or not a human could distinguish GPT-3 generated articles from human written one. As expected, as the size of the model increased, the ability for humans to distinguish the difference between a generated article and a human written one decreased. Astoundingly though, the mean human accuracy for detecting generated articles for the largest GPT-3 model was just slightly above chance at 52%.
Comprehension
One of the most extensive tasks GPT-3 was trained on was its ability to comprehend and extract meaning from text. This was tested in a varitey of ways including utilizing new words, answering questions based on prompts and facts, and general reasoning.
To evaluate the model's ability to utilize new words, the OpenAI team came up with some made up words and provided its definition to the model. From this information, the model was tasked to use the word in a sentence. Since there is no quantitative metric to measure how well a made-up word is used in a sentence, they again used a qualitative human evaluation. In most cases, the GPT-3 generated sentences that included the made-up word seemed to be proficient at using the novel word correctly. A similar test with a quantitative metric had to do with recognizing novel patterns by using SAT analogies. The model was provided SAT style analogy questions and tasked to determine which pair of words in the answer choices had the same relationship as the words in the question. In this task, GPT-3 was correct 65.2% of the time in the few-shot setting. While this may not seem too accurate, take into account that the average college applicant was correct only 57% of the time.
Another comprehension task GPT-3 was tested on was knowledge-based question answering. The model was given the PhysicalQA dataset which contains a set of common sense questions about how the world works. In this experiment, GPT-3 achieved an accuracy of 82.8% in the few-shot setting on the easy questions. Compared to a previous fine-tuned state-of-the-art model RoBERTa, GPT-3's accuracy was 3.4% higher, again showcasing its ability to outperform fine-tuned models.
The last comprehension test I wanted to mention had to do with relationships between sentences and pronoun references. GPT-3 was tested to see if it could determine which subject a pronoun was referring to. This Winograd Style task is a baseline task in natural language processing, where pronoun references are very clear to humans but ambiguous in grammatical context. Fine-tuned models designed for this task achieve almost perfect accuracy now, but GPT-3 still only falls a few points below state-of-the-art models at 88.6%. A similar task has to do with natural language inference between two sentences. Here, the model was tested to understand the relationship between two sentences. Usually, this involves determining whether or not a sentence can logically follow a given sentence. This task was evaluated on SuperGLUE's RTE dataset, where GPT-3's accuracy performed just slightly above random at 56%. I mention this test to show that while GPT-3 is a very powerful model, it cannot be generalized to every aspect of natural language processing.
Case Study
As an experiment, I decided to test the BLEU score when translating a few phrases from Slovak, my native language, into English. Since Slovak isn't a particularly highly studied language in terms of machine translation, I thought it would be interesting to see if GPT-3 could accurately translate Slovak into English. In order to test this, I came up with a set of phrases in Slovak and their respective translations into English using Google Translate. From this set of translations, I took the Slovak phrases, fed them through the GPT-3 model completion task with a few-shot prompt, and did a BLEU score evaluation from the output of the GPT-3 model and the Google Translate reference text. One of the things I noticed throughout this experiment was that the model sometimes generates different translated sentences for the same input. Nevertheless, the BLEU score still hovers around the same values. The prompt and results are shown below. The average BLEU score between GPT-3's translation and Google Translate for the ten translations was 0.7196.
Prompt: Slovak: Dobré ráno!
English: Good morning!
Slovak: Ako sa máš?
English: How are you?
Slovak: Odkiaľ si?
English: Where are you from?
Slovak:
| Slovak (Input) | Reference (Google Translate) | Candidate (GPT-3) | BLEU Score |
|---|---|---|---|
| Dnes si môžeme ísť kúpiť oblečenie do nákupného centra, ale nebudeme sa tam môcť najesť | Today we can go to the mall to buy clothes, but we will not be able to eat there | Today we can go to the mall to buy clothes, but we cannot eat there | 0.6313 |
| O druhej poobede budem doma na obed | I will be home for lunch at two in the afternoon | I'll be home for lunch at 2 o'clock | 0.3553 |
| Môžete mi poslať e-mail s dátumom a časom stretnutia? | Can you send me an email with the date and time of the meeting? | Can you send me an email with the date and time of our meeting? | 0.8555 |
| Keď sa skončí hokej, mali by sme ísť hrať hokej | When hockey is over, we should go play hockey | When hockey ends we should go play hockey | 0.5247 |
| Kúpim chladničku za sto dolárov | I'll buy a refrigerator for a hundred dollars | I want to buy a refrigerator for $100 | 0.3457 |
| Musím sa učiť na test z biológie | I have to study for a biology test | I have to study for a biology test | 1.0 |
| Poďme do parku a zahrajme si futbal | Let's go to the park and play football | Let's go to the park and play football | 1.0 |
| Môžeme mať na večeru kuracie mäso? | Can we have chicken for dinner? | Can we have chicken for dinner? | 1.0 |
| Tento víkend som išiel do domu svojich priateľov a hral videohry | This weekend I went to my friends' house and played video games | This weekend I went to my friends' house and played video games | 1.0 |
| Veľmi sa teším, keď ich zajtra uvidím hrať na koncerte | I'm very happy to see them play at the concert tomorrow | I'm very looking forward to seeing them play at the concert tomorrow | 0.4833 |
Conclusion
From this blog, we see that GPT-3 is extremely powerful and can perform better on some NLP tasks than even the state-of-the-art fine-tuned models. GPT-3 is not trained to do anything specific task; rather, it is pretrained on a massive dataset consisting of over a trillion words. When used for a specific task, the model is able to take zero, one, or a few demonstrations of the task depending on the type of experiment you want to conduct. This is ultimately what gives it the flexiblity to be applied to a variety of different domains within NLP.
For language translation specifically, it achieved BLEU scores slightly below that of some supervised NMT models. This is incredible, given it is not fine-tuned or trained for machine tranlation. When increasing from zero-shot to one-shot to few-shot, GPT-3 performed significantly better and better in translating between languages. It performed best when translating to English because the CommonCrawl dataset used to train GPT-3 contained English words 93% of the time, and foreign words 7% of the time. In my specific case study of translating Slovak into English, the model achieved an average BLEU score of 0.7196 using a few-shot setting.
In my opinion, even though GPT-3 is the latest and greatest language model to date, there is still room for improvement for these novel large-scale models. While GPT-3 proved that one pre-trained model can perform many NLP tasks and generate impressive results, it still lacks the ability to extract meaning and comprehension from text. Its synthesis techniques are gramatically sound and readable, but its contextual meaning is often repetitive, incoherent, and occasionaly contradictory. There are hypotheses that bidirectional encoder models could solve these sort of comprehension issues and create another incredible model, but until we figure out a way to truly extract meaning and generate long text that gives us coherent information, I believe GPT-3 will remain the status qou for generative language models.